Business English, Professional English, Legal English, Medical English,
Academic English etc.
Online Journal for Teachers
ESP World
ISSN 1682-3257
http://esp-world.info
English for Specific Purposes
|
Using Corpus Resources as Complementary Task Material in ESP
Alejandro Curado Fuentes
Patricia Edwards Rokowski
University of Extremadura
acurado@unex.es
pedwards@unex.es
1. INTRODUCTION
The integration of corpora or electronic text collections in ESP (English
for Specific Purposes) is viewed as a coherent course design step at university
settings (cf. J. Flowerdew, 2001; L. Flowerdew, 2001; Flowerdew, 2002;
Curado, 2001). These corpus applications include various text types -
from instruction manuals in engineering to spoken data such as the MICASE
(Michigan Corpus of Academic Spoken English) collection. A corpus-based
analysis of language also tends to play a key role in specialized language
organization and methodology (Flowerdew, 2001: 71). In agreement with
Krishnamurthy (2001: 83), two chief principles justify corpus integration
in our language program: “A corpus can give us accurate statistics”
and “a corpus can provide us with a vast number of real examples”.
A multidisciplinary framework is generally encouraged in ESP (cf. Dudley-Evans
& St. John, 1998), i.e., different subject areas or knowledge domains
can be integrated in one approach. In this regard, the constitution of
a varied corpus is highly suitable, since more than one type of ESP students
(e.g., in Business, Computer, or Tourism studies) can be encompassed.
This paper describes a particular situation where Business English is
taught by incorporating corpus-driven knowledge and communicative task
feedback. Two main goals are addressed in this relationship: Corpus material
design by focusing on language and content needs, and corpus-based data
exploitation / evaluation in the academic context. Information Technology
(IT) is selected as a multidisciplinary area not only for Business but
also Computer Studies: IT is conceived as a subject area that applies
to many others (a multidisciplinary scope), and IT use and applications
enable the performance of communicative tasks in EAP (English for Academic
Purposes).
Our intended approach aims to meet the needs described by Thompson (2002):
To make EAP teaching material reliable in terms of content novelty, and
to exploit such content according to corpus-driven itemization. In our
case, the learning situation includes IT and the university setting, but
also the future workplace (businesses and firms). In this sense, EPP (English
for Professional Purposes) is targeted as well.
In addition, we observe that, as language change tends to happen when
IT developments take place, linguistic confusion may arise in the ESP
learner. Thompson (2002), among other scholars, proposes an electronic
perspective of Internet and self-access study, based on the combination
of CALL (Computer Assisted Language Learning) and corpus-driven language
learning (see also Thurstun & Candlin [1998], Johns [1986]). Thompson
(2002) also refers to the need for setting up corpus instruments in an
effective EAP framework, since many language instructors still ignore
corpus exploitation possibilities for language teaching and learning.
Small and medium-sized corpora could be the way of meeting such shared
interests and demands in the academic and professional setting (cf. Tribble,
1998; Scott, 2000; Curado, 2002a).
2. FRAMEWORK
In this line of research, a common core focus on Information Science
and Technology leads to integrating different subject areas. IT topics
are studied in various disciplines (e.g., Business Science, Tourism, Computer
Science, Library Science, Telecommunications [Sight and Sound], and Audio-visual
Communication). It is highly important that learners from different fields
are skillful and knowledgeable at IT, because, without a command of IT,
learners would be at a clear disadvantage in a highly competitive market,
whether they are using computer resources for academic or professional
purposes. By following study plans, syllabi, and guidelines from different
universities (our own, others from Spain and abroad – cf. Curado,
2002b), subjects and topics are examined as common core across the disciplines
mentioned.
Four main subject headings can be identified in Business Science, where
different IT topics receive a significant coverage:
a. MANAGEMENT INFORMATION SYSTEMS
b. ACCOUNTING AND LAW
c. MANAGEMENT AND MARKETING
d. STATISTICS AND FINANCE
Under these, significant Business and Computer Science notions are classified
according to common topic and interest criteria in the study programs:
Database management, technical support, multimedia software, office-based
applications, effective customization, Internet use and exploitation,
web-based communications, networking, electronic mailing and publishing,
copyright protection and information ethics.
In addition, fitting genres and text types are chosen according to the
period of studies. An example is the textbook as a primary reading material
during the first year of studies, especially in the subject of Statistics,
where that genre is obligatory. Figure 1 illustrates the selection made
in our Business English corpus by following Business and Information Technology
(henceforth referred to as BIT) criteria.
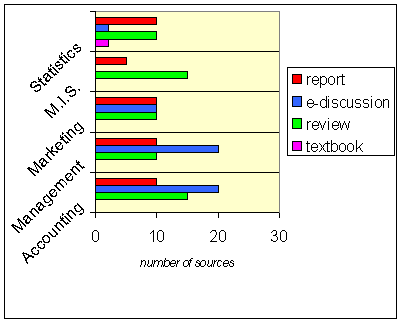
Figure 1: Contents of the BIT corpus
Second and third year subjects include M.I.S. (Management Information
Systems), Marketing, Management, and Accounting. Electronic discussions
are mainly obtained from newsgroups on the Internet. This text type exemplifies
linguistic input for intermediate/advanced learners who wish to exploit
academic and conversational writing; in fact, electronic discussions provide
a suitable blend of both registers. Reviews refer to brief descriptive
articles appearing in newspapers and other related media. They give short
evaluations of BIT products. Reports tend to have an academic register,
like textbooks and research articles; however, they can often be found
between the two in terms of complexity, and they are generally more descriptive
than instructive (cf. Martin, 1985).
3. APPROACHES TO LANGUAGE DEVELOPMENT
The process of learning is closely related to lexical intake in our approach.
Receiving the lexical input and producing it as effective output in context
are the two borders. The key is to achieve linguistic competence by activating
the received data in a process focus on language learning (cf. Hutchinson
& Waters, 1987). In this respect, the BIT corpus should serve as reference
for linguistic growth in EAP / EPP. The objective is to foster motivation
by enabling learners to perceive a relationship of their studies with
language use (Donna, 2000: 39).
Corpus Linguistics strategies and techniques are used to carry out the
corpus exploitation from a pedagogical perspective. This scope implies
a language analysis of corpus sources according to the purposes and conditions
provided by the learning setting. Firth’s views (1957) on lexical
competence are relevant, but also is Hoey’s description of lexical
priming in academic settings (2002). Other publications influencing our
work are J. Flowerdew (2001), Nation (2001), Tribble (2001), and Hunston
(2002).
John Flowerdew examines three main objectives (task, vocabulary, and grammar)
that are interrelated in the design of syllabus units (e.g. writing a
cohesive paragraph from diagrams, tables, and other visual sources in
Biology) (Flowerdew, 2001: 84). Nation (2001: 32) focuses on contrastive
analyses of vocabulary size and coverage for the university context -
how large and how relevant a university vocabulary database should be
is probed by means of computer programs (VocabProfile and Range). Tribble
(2001: 383) investigates the use of genres / text types forming small
corpora for communicative tasks. Hunston (2002: 185) refers to the important
fact that corpus material should be made available to learners, and that
their attention should be drawn to particular language features that become
highly relevant for task development.
Contextual references can be linked with lexical collocations and phrases
in the study of corpus-driven data. Four significant relationships are
surveyed in our approach, as Table 1 shows. The example is based on Gavioli
(1997: 87), who works with Geology texts.
Context & collocation
(= subject [Geology]) e.g land rift Context & phrase (= subject & genre [Geology textbook]) e.g. land rift can be defined as Context & pattern (= genre [textbook]) e.g. ______ can be defined as Context & semantic prosody (= genre & register [academic]) e.g. defined as (+ FORMAL DEFINITION) |
Table 1: Relationships between context and lexical data
These data should serve as linguistic pointers to the BIT corpus contents. In other words, extracting and classifying lexical information such as the one in Table 1 should be a preliminary step in the acquisition of corpus-based lexical knowledge. Linguistic competence is ‘trained’ by means of word- and phrase-level exercises such as word listing and concordancing. In contrast, the macro-structural stage where learners should put this knowledge to the test is the communicative task, which challenges their capacity to demonstrate their command of contextual relationships (e.g., introducing a topic in an oral report by giving a formal definition where the student uses, for example, subject-based collocations and genre-based semantic prosody).
4. LANGUAGE USE AND CORPUS INTEGRATION
4.1. Corpus use
In our experience, the application of corpus information to the ESP classroom
should be done progressively, in harmony with the students’ learning
needs. The BIT corpus built can provide useful contrastive data if, like
medicine, given in the right dose and at the right time. Access to the
corpus can provide a wider and richer view of the lexical items than if
only identified through vocabulary exercises (this observation has also
been made by Hunston [2002: 184]).
An example of corpus-driven exercise is the concordance of frequent content
words in the corpus. Some of these are nouns like data, model, management,
analysis, and market. In addition, information from not so frequent items
can contribute to building the semantic profile of words. Such elements
are less common across the genre and subject categories of the specialized
corpus, but key in their specific context (i.e., restricted to one subject
only -- e.g. the compound management control system in Management--).
A comparative exercise of BIT data with other specific corpora is also
a useful introductory way of promoting corpus-based thinking among students.
As Table 2 illustrates, medium-sized corpora such as our BIT (650,000
tokens) and IST (Information Science and Technology – 850,000) corpora,
designed and built for teaching purposes, can offer similar frequency
positions in the common area of IT In contrast, a slightly larger collection
such as the HKBSE (Hong Kong Corpus of Business Science and Economics
– James and Purchase, 1996) may differ in terms of some word rankings,
such as data, model, and analysis, and yet, be similar with regard to
other items (e.g. new, market, and example). A GE (General English) type
of collection, e.g., the BNC (British National Corpus) sampler (two million
words), can also be contrasted in this introductory view, especially in
order to give a broader scope than the Business and Information Technology
area. The overall aim is to have learners contrast word use across corpora
to induce lexical variation depending on the contextual nature (i.e.,
subject and genre) of the corpus.
| BIT (650,000) 40% # |
HKBSE (one million) 37.6% |
IST (850,000) 37.09% |
BNC (two million) Tokens 36.9% TTR |
| 27 Data 28 Model 40 Management 42 New 43 Analysis 44 Market 46 Information 48 Example 50 Number |
71 114 70 55 169 59 61 54 90 |
36 156 121 411 139 524 20 25 38 |
393 1251 769 128 1655 299 191 544 178 |
| • BIT = Business and
Information Technology Corpus • HKBSE = Hong Kong Business Science and Economics Corpus • IST = Information Science and Technology corpus • BNC = British National Corpus sampler • TTR = Token-to-Type ratio (types per 1,000 tokens) |
|||
Table 2: Comparative view of BIT data with other corpora
The instructor’s supervision along the concordancing activities
is crucial for the appropriate production of contrasted items. The analysis
should raise an awareness of lexical chunks as significant semantic units
of specific language. Some examples are those derived from contrasting
the widely used (semi-technical) items market and data. For instance,
the collocation the Stock market is examined as highly frequent in both
BIT and HKBSE; it is thus regarded as characteristic of Business and Economics
texts. In contrast, data transfer is typical in IST, while data analysis
appears more frequently in BIT. In addition, as the verb + noun co-occurrence
gather + data is checked as common across both corpora, students perceive
a lexical nexus between IST and BIT, related to the activity of electronic
data collecting.
4.2. Task development
Communicative tasks in our ESP courses usually involve from four to six
written / oral assignments to be performed and completed during the semester.
These tasks are assigned at the beginning of the course and encouraged
in groups and pairs. Some examples are the oral presentations of results
and conclusions derived from business surveys and market analyses, web
page description for project work, simulations of meetings that deal with
regional business issues, news reporting based on actual stories previously
viewed and examined, written technical reports evaluating business technology
and electronic commerce, and so on. It is important that much bibliographic
information used in the tasks comes from the BIT corpus. This content
relationship will mean that a great part of the ideas, notions, developments,
and methods in the task can and should be phrased in the specialized language.
During project work and corpus-driven classroom activities, the crucial
goal is to give no other choice to learners but to rely on BIT lexical
data for competence. For instance, their preference for market analysis
and not the analysis of the market would be a direct result of their exposition
to the corpus language. It would demonstrate their awareness of typical
BIT language use, where the noun + noun collocation is favored. As a result
of typical language identification exercises, learners also grow conscious
of their need to know certain words in specific combinations and phrases,
and of actual academic / professional use. In our view, employing a bodily
analogy if we may, the effect of corpus-driven exercises (in the brain)
is similar to weight lifting (in the body): It increases volume (= mental
capacity). In turn, communicative tasks are regarded as endurance workout;
their consistent practice leads to a steadily good condition (= language
command in the overall communicative process).
Learners often say that their linguistic mistakes in tasks are in part
caused by their lacking specific vocabulary. Figure 2 illustrates semi-technical
word use needs perceived by students (e.g., data, management, analysis,
market, new, available, run, gather, etc). More restricted items (specific
or technical), based on one subject or genre alone, are also considered
important, but to a lesser degree (e.g. a noun compound like management
production control system in Management). Grammatical elements (e.g.,
passives, modals, conditionals, etc) are demanded less according to learners’
opinions, since students already have a high-intermediate level of grammar
in our courses.
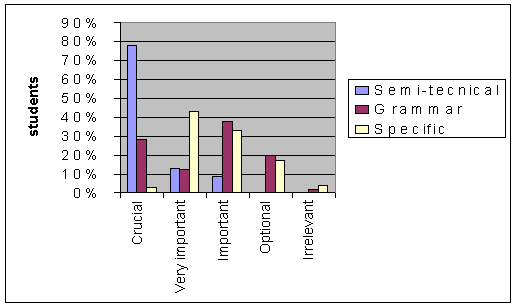
Figure 2: Learners’ evaluation of linguistic
needs for tasks
When questioned on their preferred types of tasks, learners tend to choose
two: The oral presentation given in the form of the academic lecture,
and the job interview in which they must defend their vitae as professionally
as possible. Such inclinations lead to the design of two main sets of
discourse features in the EAP / EPP settings (Table 3):
ACADEMIC / PROFESSIONAL SKILLS
MONOLOGUES (ACADEMIC -- lectures) |
DIALOGUES (PROFESSION -- interviews) |
Table 3: Sets of discourse features favored by learners in tasks
Feedback from these communicative tasks in the classroom can help to
revise the BIT corpus in terms of the academic and professional purposes
to which it is put (i.e., in terms of its language usefulness in the context
of tasks for specific purposes). Thus, when and if semi-technical items
are considered highly important, this perception comes as a result of
both developing the tasks and learning the words on a daily basis. The
condition is that learners keep an active and inquisitive mind to seek
needed words.
4.3. Reviewing the corpus data and evaluating tasks
A communicative development in tasks activates subject area knowledge
(schemata) and lexical competence (command of lexical forms, positions,
function, and meaning in a specialized type of discourse – cf. Nation,
1990). In our experience, being aware of the corpus data for task exploitation
is the first major step. However, a consecutive stage is to work with
a pre-determined lexical profile for specific purposes, in agreement with
Nation (2001).
We find that a middle “ground” of lexical use – chiefly
semi-technical word behavior—is most relevant. Students’ responses
to questionnaires handed out in class demonstrate this sense of demand
for semi-technical word use in EAP / EPP / EST (e.g., writing summaries
and giving explanations on how to run a piece of equipment). In addition,
corpus data can be revised by focusing on the sub-language areas that
bequeath a greater reward in terms of language acquisition. For example,
the use of semi-technical items in technical reports is seen as productive
(Table 4 below). The corpus is re-examined as an instrument providing
the necessary ingredients –borrowing Aston’s analogy (2000),
if we may— for the ‘cooking’ process of learning, by
which students may make their own ‘dish’ if all the ingredients
are there. The corpus data, properly segmented and facilitated to the
learner, can be integrated in the top-down analysis that every communicative
task entails, i.e., in the accomplishment of communicative events for
specific purposes.
For instance, a task demanding learners to conduct a market analysis in
which corporate companies are described, may suggest the application of
preliminary activities focusing on restricted noun + noun collocations,
as these abound in Economics report language. Table 4 provides an example
of a Fill-in-the-gap exercise that promotes this type of language.
|
||||
Table 4: Example of collocation exercise for communicative task
For the exercise in Table 4, frequent combinations like corporate law, corporate images, and corporate report, among others, should be easily spotted in the reports handed out. The wide availability of this lexical data in the corpus enables students to find relevant items. Something similar happens in the search for semantic prosody. In such a case, concordance lines containing a given connotation are reproduced for students, who must explore semi-technical language in the corpus to check for this semantic plane. Table 5 is an example of a semantic prosody activity with the verb increase, generally associated with the meaning explained by the hint provided in the exercise, and frequently appearing followed by a preposition like by.
| sales _________ by 3 million dollars per year overstate that the “true” prices _________ by around 20 percent per year the costs _________ slowly year by year, leading to higher wages sales _________ by 30%, or by a factor of 1.3 * Hint= this is a verb commonly used to refer to the expansion of economic activities (sales, buys, costs, prices, etc). |
Table 5: Concordance-based exercise to point out semantic prosody
Finally, a somewhat different case is less frequent vocabulary
use in the BIT corpus. We find that even this --more rare-- lexical behavior
should be exploited for task purposes. It should be made easily recognizable
through access to few texts in the corpus, or else, we find that students
lose heart soon in the search for these words. As a result, organizing
the corpus content in a way that learners can view technical items in
context relatively fast and clearly should be done.
An example is the distribution of genre-based items for the task of writing
short essays. Specific genre samples are selected and distributed for
student use; then, the structures demanded (collocations and phrases)
can be checked out. In this process, a corpus-driven exercise like Table
6 can provide insight for writing aims. The purpose is to seek the typical
structures given in the different texts handled, categorizing them according
to the genre where they are found. An example would be this paper describes,
being most characteristic of reports, while a personal and colloquial
expression like I think it’s gonna be would be found along different
e-discussion excerpts.
|
||||
Table 6: Corpus-driven matching exercise as complementary practice
Finally, as an illustration of specific word use in tasks (e.g., genre-based), Table 7 displays an example of a student’s written performance. Here, it was up to the learner to come up with his own choice of lexical units for the writing of the essay. The task was carried out after corpus-driven data exploitation had been conducted in class. The aim was to check if learners could produce corpus-based data on writing. This is clearly the case in Table 7, where key genre items were used, and, as a result, the teacher highlighted effective structures so that the learner might perceive his communicative strengths. Typical genre-based items were underlined and evaluated as effective use.
| This paper describes the position of good negotiators as persuaders. I think that there are different types of negotiators, bad, good, very good, and charismatic. It is important to differentiate the four types using three main characteristics: 1. being concise and clear, 2. being able to communicate verbally and emotionally, 3. being able to persuade and convince. Regarding this last premise, I think that charismatic negotiators are the best negotiators due to… |
Table 7: Example of essay introduction written by student (genre-based items are highlighted)
5. CONCLUSIONS
This paper has given a particular account of corpus-driven data and communicative
task integration in the Business English course. Two main goals have been
followed: Building corpus information in the academic context, and structuring
corpus exercises according to target language and content needs in task
performance.
The subject area of BIT (Business and Information Technology) serves as
a common core backdrop, providing feedback for Business English, but also
Computer English, given the related study programs that lead to the design
of a common corpus. BIT is approached as a subject area where both top-down
and bottom-up language analyses are possible. In the former, the learning
process is considered instrumental, a key term in ESP’s own methodology,
since corpus techniques are seen as a set of features that may corroborate
effective language acquisition (e.g., Table 7). In the latter, the focus
has been placed on corpus-driven lexis as supporting data for the design
of corpus-based activities and tasks in Business and Computer English
(e.g., Table 5).
BIBLIOGRAPHY
Aston, G. (2000) "The Learner as Corpus Designer". Proceedings
of the Fourth Teaching and Language Corpora Conference. Graz, Austria:
University of Graz.
Curado, A. (2001) “Lexical Behaviour in Academic and Technical Corpora: Implications for ESP Development”. Language Learning & Technology 5: 106-129.
Curado, A. (2002a) “Exploitation and Assessment of a Business English Corpus through Language Learning Tasks”. ICAME Journal: Computers in English Linguistics 26: 5-32.
Curado, A. (2002b) A Lexical Common Core in English for Information Science and Technology. Cáceres: Servicio de Publicaciones de la Universidad de Extremadura.
Donna, S. (2000) Teach Business English. Cambridge: Cambridge University
Press.
Dudley-Evans, T. & M.J. St. John (1998) Developments in ESP. A Multidisciplinary
Approach. Cambridge University Press.
Firth, J.R. (1957) “A Synopsis of Linguistic Theory. 1930-1955”. In J.R. Firth (ed.) Studies in Linguistic Analysis. Oxford: Basil Blackwell.
Flowerdew, J. (2001) "Concordancing as a Tool in Course Design". In M. Ghadessy, A. Henry and R.L. Roseberry (2001) Small Corpus Studies and ELT. Studies in Corpus Linguistics. Amsterdam: John Benjamins.
Flowerdew, L. (2001) “The Exploitation of Small Learner Corpora in EAP Materials Design”. In M. Ghadessy, A. Henry and R.L. Roseberry (2001) Small Corpus Studies and ELT. Studies in Corpus Linguistics. Amsterdam: John Benjamins.
Flowerdew, L. (2002) "Corpus-based Analysis in EAP". In J. Flowerdew (Ed.) Academic Discourse. London: Longman.
Gavioli, L. (1997) “Exploring Texts through the Concordancer: Guiding the Learner”. In Wichmann, A. et al. (Eds.) Teaching and Language Corpora. London: Longman.
Hoey, M. (2002) "The Priming of Lexis". In G. Aston et al. (Eds.) Proceedings of the Fifth Teaching and Language Corpora Conference. Bertinoro, Italy: University of Bologna.
Hunston, S. (2002) Corpora in Applied Linguistics. Cambridge: Cambridge University Press.
Hutchinson, T. & A. Waters (1987) English for Specific Purposes: A learning-centred Approach. Cambridge: Cambridge University Press.
James, G. & J. Purchase (1996) English in Business Studies and Economics. A Corpus-based Lexical Analysis. Hong Kong: The Hong Kong University of Science and Technology.
Johns, T. (1986) “Micro-Concord: A Language Learner’s Research Tool”. System 14 (2): 151-162.
Krishnamurthy, R. (2001) “The Science and Technology of Corpus. Corpus for Science and Technology”. In G. Aguado and P. Durán (Eds.) La investigación en lenguas aplicadas: enfoque multidisciplinar. Madrid: Universidad Politécnica.
Martin, J.R. (1985) Factual Writing: Exploring and Challenging Social Reality. Victoria: Deakin University Press.
Nation, I.S.P. (1990) Teaching and Learning Vocabulary. Boston: Heinle & Heinle Pub.
Nation, P. (2001) "Using Small Corpora to Investigate Learner Needs: Two Vocabulary Research Tools". In M.
Ghadessy, A. Henry and R.L. Roseberry (2001) Small Corpus Studies and ELT. Studies in Corpus Linguistics. Amsterdam: John Benjamins.
Scott, M. (2000) “Reverberations of an Echo”. En B. Lewondowska-Tomaszczyk, B. y P.J. Melia (Eds.) Practical Applications in Language Corpora. Frankfurt am Main: Peter Lang.
Thompson, P. (2002) "What Use are Corpora in the Teaching of EAP". In G. Aston et al. (Eds.) Proceedings of the Fifth Teaching and Language Corpora Conference. Bertinoro, Italy: University of Bologna.
Thurstun, J. & C.N. Candlin (1998) “Concordancing and the Teaching of the Vocabulary of Academic English”. ESP 17: 20-34.
Tribble, C. (1998) “Improvising Corpora for ELT: Quick and Dirty Ways of Developing Corpora for Language Teaching”. In B. Lewandowska-Tomaszczyk and P.J. Melia (eds.) Practical Applications in Language Corpora. Lodz: Lodz University Press.
Tribble, C. (2001) "Small Corpora and Teaching Writing". In M. Ghadessy, A. Henry and R.L. Roseberry (2001) Small Corpus Studies and ELT. Studies in Corpus Linguistics. Amsterdam: John Benjamins.
Corpora used
• BIT = Business and Information Technology Corpus (A. Curado, 2002 -- classroom application & research)
• BNC = British National Corpus sampler (Burnard, L. & M. Barlow, 1998 -- sampler with various genres)
• HKBSE = Hong Kong Business Science and Economics Corpus (G. James & J. Purchase, 1996 -- textbook research)
• IST = Information Science
and Technology corpus (A. Curado, 2000 -- classroom application &
research)
Home ESP Encyclopaedia Requirements for Papers Guidelines for Authors Editors History